

D-Edit: A New Era of Image Editing with Diffusion Models Introduction:
Introduction
Welcome back to our latest blog post, where we continue to showcase groundbreaking research projects from our team. Today, we're diving into another remarkable development: a revolutionary framework for image editing called Disentangled-Edit (D-Edit). Based on diffusion models, this framework enables complex image manipulation through 'prompt' control, providing unprecedented levels of precision and creativity in image editing. This framework is based on diffusion models and allows for complex image manipulation using 'prompt' control, enabling unprecedented levels of precision and creativity in image editing.
Traditional Challenges
Traditional image editing methods often struggle with altering specific objects within an image without affecting the rest of the scene. This can lead to inconsistencies and unnatural-looking results. There is a clear need for an editing technique that can disentangle object-prompt interactions and provide granular control over individual elements within an image.
D-Edit Framework
D-Edit addresses these challenges by introducing a unique approach to disentangling item-prompt interactions. Each item in the image, such as an object or background, is associated with a special learned prompt. This disentanglement allows for text-based, image-based, mask-based editing, and item removal, providing a versatile approach to editing operations.
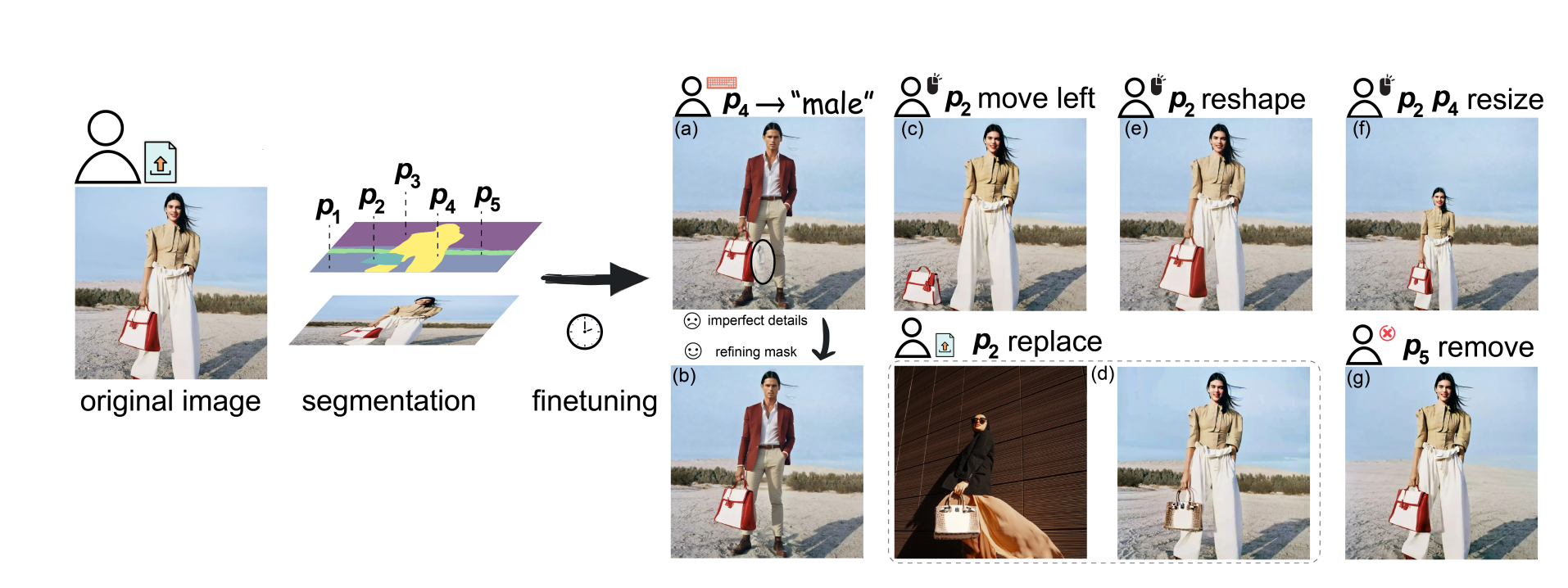
Key Features:
- Prompt-Based Editing: Using prompts, users can specify detailed editing instructions, ensuring that the edited image remains consistent with the original context.
Disentanglement: The disentanglement of item-prompt interactions ensures that editing one part of the image does not affect unrelated parts, maintaining the integrity of the original image.
- Versatility: D-Edit supports various editing modes, including text-based, image-based, and mask-based editing, making it a flexible tool for a wide range of applications.
Experiments and Results
Through extensive experiments, we demonstrate that D-Edit outperforms existing editing methods, producing more realistic, harmonious edits that better preserve the original image's characteristics. The key performance indicators include the retention of original image content while ensuring semantic alignment with the editing guidance.
Practical Applications
The D-Edit framework has significant potential for creative tasks and could enhance user interaction with AI-generated content. It opens up new possibilities for applications such as virtual try-ons, interior design, and 3D spatial understanding. For example, users can easily visualize how different furniture or decor items would fit into their rooms, making informed decisions about layout and aesthetics.
Future Work
Looking ahead, we propose further exploration into the integration of D-Edit with 3D spatial understanding technologies. This could significantly streamline the image editing process and enhance the user experience by providing more intuitive and interactive tools for manipulating digital environments.
Conclusion
In conclusion, D-Edit represents a major step forward in the field of image editing. Its ability to generate high-quality, consistent, and controllable edits opens up exciting possibilities in various industries, from fashion to interior design. With further advancements in 3D spatial understanding, we envision a future where the gap between digital visualization and physical reality is virtually non-existent. Stay tuned for more updates as we continue to push the boundaries of what's possible with AI.

